
How Is AI a Money Maker?

Soon on Wealth Systems were are launching a special series focusing on applying AI to wealth building and preservation. We’ve been getting lots of requests for this series. It’s going to be epic (and tactical).
It’s going to be exclusively for paid members.
Also, friendly reminder: We are raising the price on August 29, 2025. Going from $12/month to $17/month.
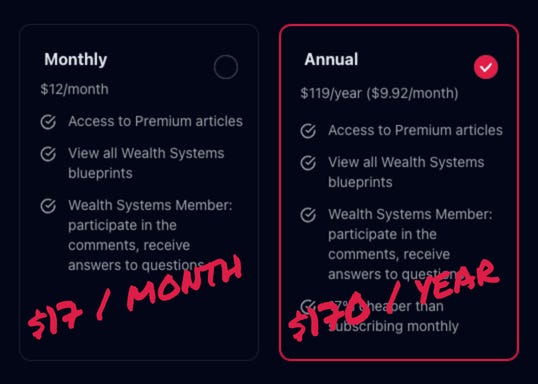
Then, we are increasing price AGAIN to $22/month on December 31, 2025.
Subscribe now to lock-in today’s rate! You have 11-days to secure the current price.
By the end of this year we will have increased price from $12 a month to $22. Lock in $12/month. Right now: